

When Andrej Karpathy, the acclaimed AI expert from Stanford and OpenAI, recently shared new insights into large language models (LLMs), I was fascinated. He revealed an image that vividly depicted how these complex algorithms operate behind-the-scenes.
I’m a firm believer that teaching others is one of the best methods for deepening your own understanding. So I’ve synthesized Karpathy’s key points into this plain-language explainer of LLMs
Understanding Large Language Models (LLMs)
Large language models (LLMs) are a groundbreaking artificial intelligence technology that has the potential to revolutionize how humans interact with computers.
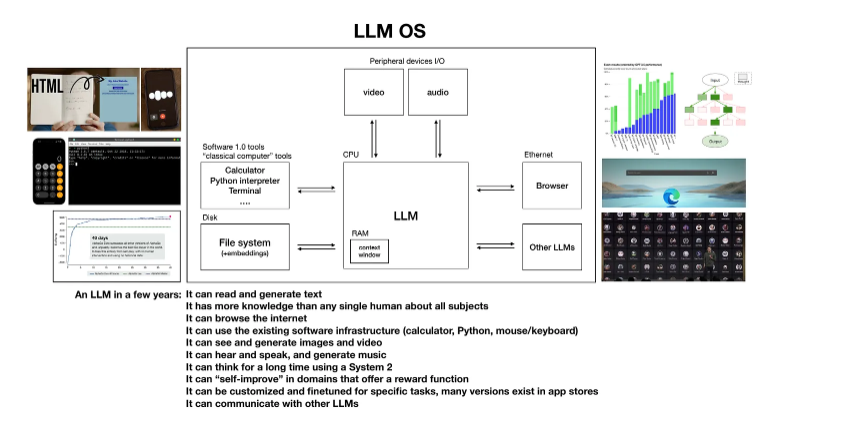
What Exactly is a Large Language Model?
A large language model is a complex neural network that has been trained on massive volumes of text data from the internet – often hundreds of billions of words. It learns the patterns and relationships between words in this vast dataset. The model tries to predict the next word in a sequence given the previous words. Over time and with enough data, the LLM becomes incredibly skilled at generating fluent, coherent text by capturing the nuances of natural language.
Leading examples of LLMs include models like GPT-3 by OpenAI and Claude by Anthropic, with billions of parameters. LLMs are also referred to as “foundation models” because many AI applications are built by fine-tuning them for specialized tasks.
How Do Large Language Models Work?
You can think of a LLM as an extremely advanced autocomplete, similar to Smart Compose in Gmail. Only instead of predicting a single next word, it can generate entire sentences, passages and documents.
Under the hood, the LLM is running probabilistic predictions of possible next tokens. When prompted with “The cat sat on the…”, it assigns percentages to the most logically fitting words that could follow. The top choice becomes part of the sequence, and this cycle repeats word-by-word.
Given enough dataset scale and compute power, LLMs can reach stunning fluency. The downside is they may also “hallucinate” – inventing plausible but totally fictional information when highly uncertain. Tools like search integration help ground them.
How Are LLMs Trained?
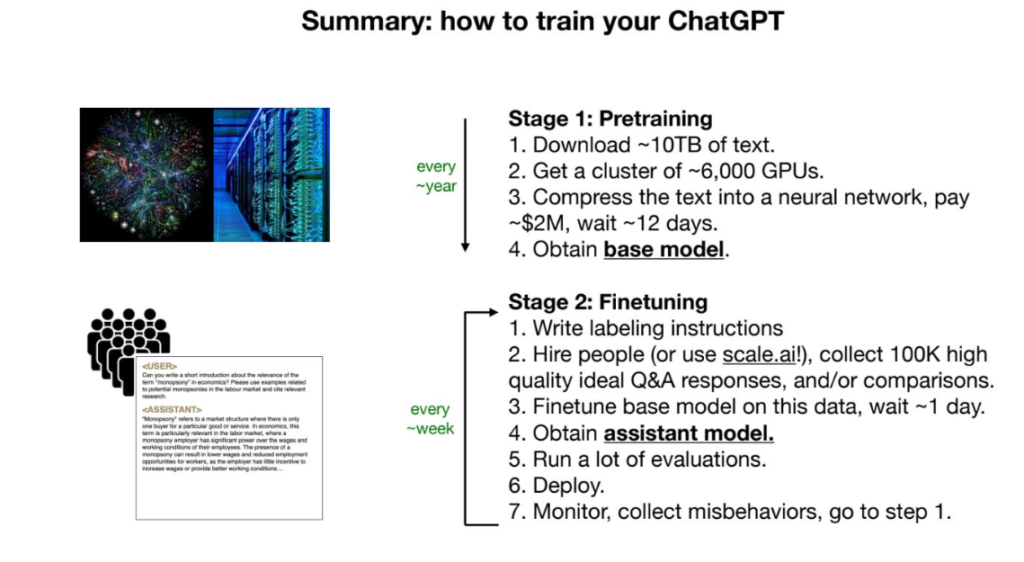
Training a LLM involves two key stages:
- Pre-training
This compresses vast volumes of text data – websites, books, Wikipedia etc. – into a neural network on powerful GPU servers. It creates a base model capturing intricate word relationships. Only a few organizations can invest to produce the largest models. - Fine-tuning
The base model then gets tailored to improve performance for specific use cases. For example, a company developing a conversational AI assistant would fine-tune the model on thousands of real chat logs. Fine-tuning is more accessible for commercial use.
Between the massive datasets and heavy computation required, training costs for cutting-edge LLMs easily run into millions of dollars. This is why most real-world applications instead fine-tune existing open-sourced base models.
How Can LLMs Transform the Future?
As LLMs grow more advanced, they could evolve into a multi-purpose “language operating system” that powers a wide range of intelligent services:
- Information concierge
- Creative content generation
- Intelligent search
- Data analysis
- Programming assistance
- Personalized recommendations
- Simulation of experts
The future possibilities are tremendously exciting. Equally important is ensuring these models develop safely, avoid harmful biases and augment rather than replace human intelligence. Responsible governance of this technology will enable realizing its benefits while minimizing risks.
The era of large language models is just beginning, but by demystifying how they operate, we can better collaborate with them in both business and society.